Muchos se hacen la pregunta de como migrar de Python 2 a 3, por el motivo que un día la versión de python 2 quede obsoleta y para un proyecto necesiten un código que este hecho con Python 3, teniendo ya el código en Python 2 pero lo necesitan urgentemente, no disponiendo de tiempo para trasladarlo a la nueva versión.
Los desarrolladores del proyecto Python, han creado una herramienta de traducción automatizada que hace el traslado de Python 2 a 3 de forma sencilla. 2to3 es un programa de Python que lee el código fuente de Python 2.x y aplica una serie de fijadores para transformarlo en código Python 3.x válido. La biblioteca estándar contiene un rico conjunto de fijadores que manejarán casi todo el código. El programa 2to3 tiene una libreria de apoyo que le permite con facilidad hacer la traducción y se llama lib2to3, sin embargo, es una libreria flexible y genérica. por lo que permite escribir tus propios fijadores. Lib2to3 también podría adaptarse a aplicaciones personalizadas en las que el código Python necesita ser editado automáticamente.
Usando 2to3
Normalmente 2to3 se instalá con el intérprete de Python como un script y se encuentra en el directorio de Tools/Script de la raíz de la carpeta donde se instaló Python. Esta herramienta es sencilla de utilizar, ya que los argumentos básicos son una lista de archivos o directorios a transformar. Si bien es cierto, que esta herramienta no es perfecta, es recomendable repasar el código generado automáticamente para asegurarnos que el proceso se ha realizado correctamente. Ejemplo de script en Python 2 que lo trasladaremos a Python 3 con esta herramienta:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
def saludo(nombre):
print "Hola, {0}!".format(nombre)
print "¿Cual es tu nombre: ?"
nombre = raw_input()
saludo(nombre)
Ahora este script lo guardamos con el nombre de ejemplo.py y comprobamos que funciona, ejecutandolo con el comando:
$ python ejemplo.py
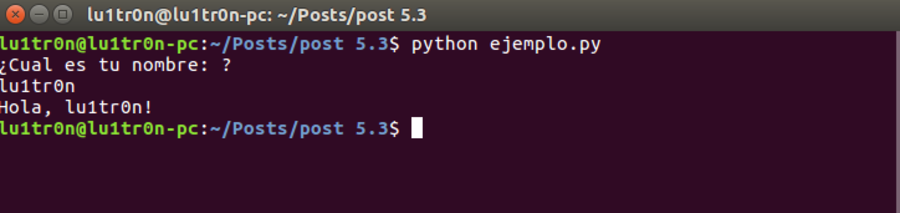
Captura de pantalla de la ejecución del script hecho con Python 2, como se observa, no hay error alguno. Ahora procedemos a convertir el script a Python 3, ejecutando el comando siguiente:
$ 2to3 ejemplo.py
El resultado de la ejecución del comando anterior nos muestra el resultado siguiente, como se puede observer en la captura mostrada aqui:
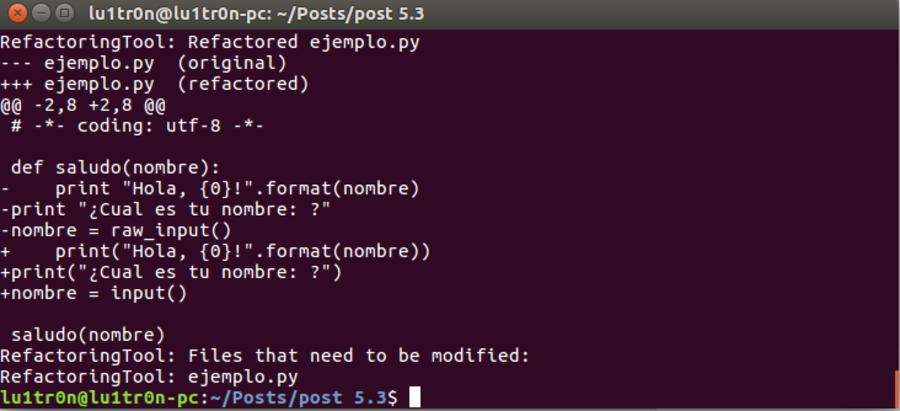
Como se puede ver en la imagen anterior, se imprime un diff del script original. Los signos de resta nos indican la instrucción original del script y los signos de suma nos indican los cambios que sufrió y por lo cual se ha cambiado a instrucciones de Python 3, como se observe en la primera linea modificada se cambio los espacios del print por paréntesis, ya que en Python 3 para imprimir un mensaje se debe escribir con paréntesis, sino mostrara un error. En la siguiente linea se observa que la instrucción raw_input() fue cambiada por input(), es un cambio que sufrió la instrucción entre las dos versión. Este es un pequeño ejemplo de como funciona la herramienta de traducción.
Ahora este cambio solo se muestra en pantalla pero no se sobreescribe en el script original, si deseamos que este cambio sea permanente, debemos agregar un argumento al comando.
$ 2to3 -w ejemplo.py
Argumento -w: Se realiza una copia de seguridad del archivo original( a menos que se incluya -n para que no se realice la copia de respaldo). La escritura de los cambio se realizará permanentemente en el archivo. El resultado final sera como se puede ver en la imagen, debe aparecer el archivo ejemplo.py y ejemplo.py.bak, juntos como resultado del comando realizado anteriormente.
Resultado final de archivo que se convirtió a Python 3:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
def saludo(nombre):
print("Hola, {0}!".format(nombre))
print "¿Cual es tu nombre: ?"
nombre = input()
saludo(nombre)
Como se observa es un sencillo ejemplo de traducción entre versiones de Python, ahora se realizará un ejemplo más avanzado con un script con más líneas de código. Para el siguiente script no se explicara con detalle cada línea de código, ya que para este tutorial no es el caso enseñar Python, sino mostrar una de las tantas herramientas que posee y que nos ahorra trabajo.
#!/usr/bin/env python # -*- coding: utf-8 -*- # # Programmer: Luis Navarro # # Librery import feedparser from bs4 import BeautifulSoup as BS import unicodedata # Data url url = 'http://one--anime.blogspot.com/rss.xml' # Instance URL data = feedparser.parse(url) # Count entries totalEntries = len(data.entries) print '##########################################################' print 'Nombre del Blog:\t\t' + data.feed.title print 'Url del Blog:\t\t\t' + data.feed.link print 'Descripcion del Blog:\t\t' + data.feed.description print '##########################################################' # Iterate each post for post in data.entries: # Array Empty info = [] imagenes = [] # Data for process html = post.summary_detail.value soup = BS(html, 'lxml') print 'Titulo del Post: ' + post.title print 'Fecha de Publicacion: ' + post.published for t in soup.find_all('div'): info.append(t) busqueda = '' if len(info) > 0: if len(info[0].text) == 0: if len(info[2]) == 0: # pass busqueda = info[1].text # Find all the images of Post for img in soup.find_all('img'): imagenes.append(img['src']) else: busqueda = info[0].text # Synopsis # Data where word begins positionSipnosis = busqueda.find('Datos') print busqueda[:positionSipnosis] # Title positionTitleEnd = busqueda.find('Tipo:') print busqueda[(positionSipnosis+5):positionTitleEnd] # Pictures print imagenes print '\n'
Como se observa en el script es un ejemplo donde lo que hace es conectarse a una pagina y hacer web crawler para obtener información de ella, este script se convertirá a Python 3 para mostrar un ejemplo avanzado con esta herramienta. Ahora se aplicará el comando y se mostrará el resultado del script:
#!/usr/bin/env python # -*- coding: utf-8 -*- # # Programmer: Luis Navarro # # Librery import feedparser from bs4 import BeautifulSoup as BS import unicodedata # Data url url = 'http://one--anime.blogspot.com/rss.xml' # Instance URL data = feedparser.parse(url) # Count entries totalEntries = len(data.entries) print('##########################################################') print('Nombre del Blog:\t\t' + data.feed.title) print('Url del Blog:\t\t\t' + data.feed.link) print('Descripcion del Blog:\t\t' + data.feed.description) print('##########################################################') # Iterate each post for post in data.entries: # Array Empty info = [] imagenes = [] # Data for process html = post.summary_detail.value soup = BS(html, 'lxml') print('Titulo del Post: ' + post.title) print('Fecha de Publicacion: ' + post.published) for t in soup.find_all('div'): info.append(t) busqueda = '' if len(info) > 0: if len(info[0].text) == 0: if len(info[2]) == 0: # pass busqueda = info[1].text # Find all the images of Post for img in soup.find_all('img'): imagenes.append(img['src']) else: busqueda = info[0].text # Synopsis # Data where word begins positionSipnosis = busqueda.find('Datos') print(busqueda[:positionSipnosis]) # Title positionTitleEnd = busqueda.find('Tipo:') print(busqueda[(positionSipnosis+5):positionTitleEnd]) # Pictures print(imagenes) print('\n')
Los cambios que se hacen no afectan en el funcionamiento del script, ya convertido y la lógica aplicada se mantiene pero siempre es conveniente revisar el script por los cambios que puede sufrir. Los comentarios y la sangría se mantiene exactamente igual durante todo el proceso de traducción.
De forma predeterminada, 2to3 ejecuta un conjunto de fijadores predefinidos. El argumento -l muestra todos los fijadores disponibles. Un conjunto explicito de fijadores para ejecutar se puede dar con -f. Del mismo modo, -x deshabilita explicitamente un fijador. El siguiente ejemplo ejecuta sólo los modulos y fijadores has_key:
$ 2to3 -f imports -f has_key ejemplo.py
Todo lo mostrado anteriormente se puede encontrar en la documentación oficial de la herramienta y muchos más argumentos que pueden mejorar la calidad del resultado final. En futuros tutoriales se mostrará mas herramientas que nos permite ahorrar trabajo y automátizar nuestras tareas. @happyday



0 comentarios